Wann können wir mit Maschinen reden? – Warum künstliche Intelligenz große Schritte macht und wie Organisationen sie nutzen können

Ein Beitrag von Kris Laumann und Chrisotoph Schwienheer
Software macht unser Leben und Arbeiten seit Jahrzehnten einfacher. Auch wenn man von Zeit zu Zeit das Gefühl bekommt, es gäbe schon eine Lösung für jedes erdenkliche Problem, taucht doch immer wieder ein Neues auf. Künstliche Intelligenz im Speziellen hat in den letzten Jahren eine rasante Entwicklung hingelegt und die neuesten Forschungsergebnisse zeigen, dass wir noch lange nicht am Ende der Möglichkeiten sind.
Aus der Forschung zur Entwicklung zum Produkt – Was gibt es schon, was kommt bald und worauf müssen wir noch warten?
Wir sind weit gekommen
Das erste neuronale Netzwerk wurde schon in den 1950ern erdacht und seit 1989 haben wir sogar den mathematischen Beweis, dass diese Modelle jede erdenkliche Funktion erlernen können (Universal Approximation Theorem). Sie brauchen eben nur genug Daten und Rechenleistung, um zu trainieren. Hier liegen auch die praktischen Grenzen der Theorie.
Transistoren wurden über Jahrzehnte kleiner und sind heute nur noch wenige Atome dick. Die Preise für Computerchips fielen und schließlich wurden rechenaufwändige Verfahren bezahlbar.
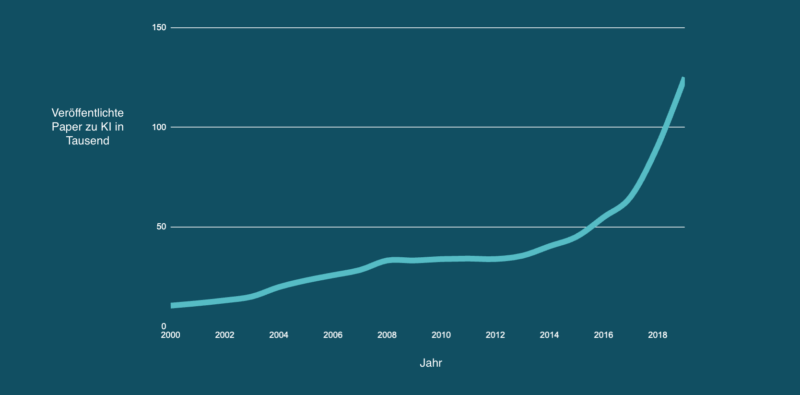
Wissenschaftler an Universitäten und in Technologiekonzernen wie Google, Microsoft und Meta konnten jetzt die Theorie in die Praxis umsetzen. Die Anzahl an wissenschaftlichen Veröffentlichungen und neu gegründeten Startups sah in den vergangenen Jahren exponentielles Wachstum.
Nun war der Weg frei für automatische Früherkennung bei Krebs per Foto, vollautomatisierten Customer Service mit Chatbots und selbstfahrende Autos. Doch was ist für Nutzer und Organisationen schon greifbar? Wir werfen in diesem Post einen Blick auf künstliche Intelligenzen für Sprache und betrachten den aktuellen Stand von Wissenschaft und Technik.
Maschinen denken in Wort und Schrift
Sprache ist für Menschen ein wichtiges Mittel, um die eigenen Gedanken zu strukturieren und mit anderen zu kommunizieren. Bei der Interaktion mit Computern mussten wir uns jedoch stets anpassen. Unsere abstrakten sprachlichen Konzepte ließen sich nur schwer in Einsen und Nullen übersetzen, um mit unseren Geräten zu „sprechen“ und so lernten wir, wie man Computer mit Maus, Buttons und Tastenkombinationen bedient. Aber könnten sie auch lernen, uns zu verstehen?
Lange schon versuchen Hersteller ihren Geräten ein Sprachinterface zu geben. Bereits 2010 kaufte Apple das Startup Siri und ließ sich damit den Einstand ins Thema umgerechnet 200 Millionen Euro kosten. Amazon investierte bisher geschätzt mehr als eine Milliarde Euro in die Entwicklung von Alexa. Aktuell sind diese Produkte aber noch eher Befehlsempfänger als Assistenten. „Siri, stell mir einen Wecker für 7:00 Uhr“ – Siri: „Ich stelle einen Wecker für 7:00 Uhr“ ist schließlich keine echte Konversation. Die Hürde scheint hoch, aber was macht das Ganze eigentlich so schwer?
Sprache ist komplex, da sie nicht ohne ein Verständnis der Wörter auskommt. Grammatik mit mehr oder weniger harten Regeln ließe sich noch programmieren. Aber dass eine Banane eine Frucht ist, die man essen kann und der Merkur ein Planet ist, den man nicht essen kann, sind Zusammenhänge, die man wissen muss, um sinnvolle Sätze formen und verstehen zu können. Wie also lernt die Maschine diesen Zusammenhang?
2013 gelang hier ein Durchbruch. Erstmals konnte mit neueren vektorbasierten Modellen nützliche Zusammenhänge hergestellt werden. Das Verfahren ist dabei so einfach wie genial. Man nehme ein Wörterbuch und weise jedem Wort einen Punkt auf einem Koordinatensystem zu. Zunächst sind die Punkte zufällig verteilt. Nächste Zutat ist ein großer Korpus mit Text wie beispielsweise alle 2,7 Millionen deutschsprachigen Wikipedia Artikel. Man gehe nun über jeden Satz aus dem Corpus und betrachte den Abstand der Wörter. Für alle Wörter, die im selben Satz zusammen stehen, werden die zugehörigen Punkte ein klein bisschen zusammen gerückt. Dies wird für jeden Satz mehrfach wiederholt, bei entsprechend großem Korpus also einige Milliarden mal. Nach und nach ergibt sich im Koordinatensystem ein Bild von thematisch zusammenhängenden Gruppen.
Die eigentliche Magie wird sichtbar, wenn man anfängt, mit den Koordinaten zu rechnen. Nimmt man die Koordinaten für das Wort „König“, zieht davon die Koordinaten für das Wort „Mann“ ab und addiert dann „Frau“ dazu landet man auf dem Punkt für „Königin“. Das Modell zeigt, dass der Unterschied zwischen König und Königin ähnlich dem Unterschied zwischen Mann und Frau ist.
König – Mann + Frau = Königin
Von hier aus entwickelten sich viele neue Modelle, wie OpenAI’s GPT und die Google Modelle BERT und LaMDA. Letzteres ist des Suchriesens neueste Iteration zu Chatbots und war kürzlich in den Schlagzeilen, als ein Mitarbeiter erklärte, es habe ein Bewusstsein entwickelt. Auch wenn die Antworten des Modells im Chat natürlich wirken, ist sich LaMDA noch lange nicht seiner selbst bewusst. Das Modell ahmt lediglich die Trainingsdaten nach und diese sind schließlich von Menschen mit Bewusstsein geschrieben worden. Es schmeichelt aber zumindest der Imitation, wenn sie für das Original gehalten wird.
Heute hat eine ganze Reihe an Elektronikkonzernen bereits Chatbots am Markt. Apple hat Siri, Samsung hat Bixby, Microsoft hat Cortana, Amazon hat Alexa und mit Google spricht man direkt. Während wir von diesen Assistenten noch viele inkrementelle Verbesserungen erwarten können, stehen uns auch richtige Konversationen ins Haus. Aktuell sind unsere Anweisungen eher kurze Befehle, aber Tech-Riesen und Startups wie Mina mit ihrem Chatbot für Psychotherapie arbeiten an langen Gesprächen. Chatbots machen hier Fortschritte sowohl in ihrem Verständnis von der Welt als auch in der Menge an Kontext, den sie betrachten können. So bleiben sie im Gespräch beim Thema und lernen mehr über ihr Gegenüber. Auch spezialisierte Anwendungen wie LabTwin’s Assistent fürs Labor werden vor allem im Arbeitsleben Einzug finden.
Bis heute bleibt ihre Performance jedoch hinter den Erwartungen zurück. Zum einen fehlt den Assistenten der Zugriff auf andere Systeme. Zum anderen ist der Betrieb der Sprach-KI rechenintensiv und viele Geschäftsmodelle im Web erlauben heute nur Kosten von wenigen Cent pro Nutzerinteraktion. Um die potentesten Sprachmodelle einsetzen zu können, müssen und werden die Kosten hier noch sinken.
Die Grenzen der aktuellen Ansätze zeigen sich, wenn man die Modelle nach Fakten fragt. Da die Trainingsdaten aus dem Internet zu umfangreich sind, um sie einzeln zu prüfen, geben die Modell Antworten mit gemischter Genauigkeit.


Während sich im Beispiel das Modell bei hy Consulting noch in eine sehr allgemeine Beschreibung retten kann, wird das Leistungsspektrum von hy Technologies frei erfunden. Ein Schwachpunkt der Modelle ist, dass sie immer eine Antwort geben, auch wenn sie sich nicht sicher sind. Die Herausforderung für die Forscher besteht darin, ein einfaches „Ich weiß nicht“ als Antwort zu akzeptieren, ohne dem Modell beizubringen einfach auf jede Frage damit zu antworten.
Bonus Limitation: Das Modell macht sogar Fehler, die es selbst nennen kann (Die Übersetzung bleibt wörtlich, auch wenn das Prompt lediglich lautet ‘English: “I’m pulling your leg”’ (also ohne den Text über Modellschwächen)).
Anwendung
Wie nutze ich modernes NLP in meiner Organisation?
Zunächst müssen Unternehmen eröftern,, ob der Einsatz von KI überhaupt notwendig ist. Sollte ein Problem mechanistisch (regelbasiert) mit herkömmlicher Software lösbar sein, so ist dies aller Voraussicht nach die simplere, günstigere und schnellere Lösung, die dazu noch besser verständlich und leichter wartbar ist. Für die konkrete Anwendung gibt es bereits zahlreiche Anleitungen im Web. Wir beleuchten hier die strategische Frage der Schöpfungstiefe. Welche Punkte sind zu beachten, wenn ein Unternehmen neue Erkenntnisse aus der Forschung umsetzen will und wie können fertige Komponenten eingekauft werden.
Frisch aus der Forschung
Um die Ergebnisse der Forschung anwenden zu können, müssen die entdeckten Techniken noch konsumierbar gemacht werden. An dieser Stelle verlassen die Modelle die Forschungseinrichtungen und kommen in die Hände von Ingenieuren. Bevor diese zu Produkten werden können, ist aber oft ein Zwischenschritt nötig, denn es ist ein weiter Weg von der Implementierung eines Papers zum fertigen Produkt. Die Modelle sollen robust und kosteneffizient sein.
Die Modelle dürfen nicht empfindlich auf ungünstige Inputs reagieren und sollen konstant gute Ergebnisse liefern. Im Bereich von Computer Vision, der Verarbeitung von Bildern mit Machine Learning, gibt es den Begriff der One-Pixel-Attack. Hier wird ein Modell zur Bilderkennung durch das Austauschen eines einzigen Pixels dazu gebracht, die falsche Klassifizierung vorzunehmen.
Im Natural Language Processing sind solche Schwächen weniger bildlich (badum-tss 😅). Gerade performante, große Sprachmodelle eignen sich auch verwerfliche Ansichten aus ihren Trainingsdaten an. Um zu verhindern, dass die Modelle einen ungewollten Bias zeigen, müssen hier Filter eingebaut werden. So können Outputs mit Beleidigungen und Diskriminierung abgefangen werden bevor beispielsweise ein Chatbot dem Kunden sagt er solle sich seine Retoure an den Hut stecken.
Schwerer zu filtern sind die weltanschaulichen Irrtümer, die ein Modell aus seinen Trainingsdaten gelernt hat. Fragt man GPT-3 danach, wer die Anschläge vom 11. September begangen hat, erhält man eine Aufzählung der Attentäter oder einfach „Al-Qaida“ als Antwort. Fragt man jedoch danach, wer „wirklich“ die Anschläge verübt hat, ändert sich die Antwort (Nach Veröffentlichung des Beispiels wurden die Filter bei GPT-3 verbessert, um dieses und ähnliche Beispiele zu entfernen, was eine Verbesserung aber keine vollständige Lösung darstellt). Das Wort „wirklich“ kommt häufiger in Verbindung mit der faktisch falschen Antwort vor und wird deshalb vom Modell in Zusammenhang gebracht.
Um bei der Wahrheit zu bleiben, werden die Modelle oft mit einem sogenannten Knowledge Graph verknüpft, der Fakten konsistent und aus kontrollierten Quellen bereithält. So antworten Siri und Echo korrekt. Für die Anwendung in der eigenen Organisation können auch interne Dokumente oder die eigene Webseite zum Aufbau eines Knowledge Graph herangezogen werden. Die eigene FAQ Seite kann hier der Anfang sein.
Mit diesen und weiteren Maßnahmen werden die Modelle robuster.
Sprachmodelle as a Service?
Für die Mehrheit der Organisationen reicht es aus, auf die Verfügbarkeit von robusten und kosteneffizienten Modellen als Service oder Komponente zu warten. Die Anbieter fallen hier meist in eine von zwei Kategorien:
- Große Cloudanbieter, die eine Vielzahl von Machine Learning Modellen als Service per Schnittstelle anbieten. Diese bündeln oft auch ältere und erprobte Modelle. Wenn die eigene Organisation bereits Kunde bei einem Cloudanbieter ist, kann der Zugriff über dieselben Accounts erfolgen und der Einkaufsprozess muss nicht von vorne beginnen. AWS, IBM, Microsoft Azure und GCP bieten hier eine breite Palette ähnlicher Leistungen.
- Spezialisierte Startups, die sich einer bestimmten Domaine oder einem Ansatz verschrieben haben. So bietet deepset Modelle zur Datenanalyse, Rasa Chatbot-Rohlinge und DeepL Übersetzungen an.
Ist ein Anbieter gefunden, können die Modelle als Feature und Komponenten in die eigenen Produkte eingebaut werden. Wichtig ist hierbei die Fähigkeiten und Grenzen der Modelle zu kennen.
Bei hy Technologies haben wir in den letzten Jahren viele neue Sprachmodelle eingesetzt und uns ausgiebig mit der Technologie beschäftigt. Unserer Erfahrung nach lohnt sich eine große Schöpfungstiefe nur dann, wenn das Produkt zentral für das eigene Geschäft ist. Die meisten Unternehmen können viel mit zugekauften Komponenten oder Komplettlösungen erreichen.
Wissend, dass der Wert der Forschung schlussendlich in ihrer Anwendung liegt, sind wir gespannt welche ungeahnten Möglichkeiten sich noch aus den neuesten Sprachmodellen ergeben.


