Can the robots talk? – Why artificial intelligence is making big strides and how organizations can use it

03.11.2022 – An article by Kris Laumann and Chrisotoph Schwienheer
Software has been making our lives and work easier for decades. Even if you get the feeling from time to time that there is already a solution to every conceivable problem, there is always a new one that pops up. Artificial intelligence in particular has developed rapidly in recent years and the latest research results show that we are far from done.
From research to development to the product – what is already available, what is coming soon and what do we have to wait for?
We’ve come a long way
The first neural network was invented back in the 1950s, and since 1989 we even have mathematical proof that these models can learn any function imaginable. They just need enough data and computing power to train. This is where the practical limits of the theory lie.
Transistors have become smaller over the decades and are now only a few atoms thick. The prices for computer chips fell and finally computationally intensive processes became affordable.
Scientists at universities and in technology companies such as Google, Microsoft and Meta have now been able to put theory into practice. The number of scientific publications and newly founded startups has seen exponential growth in recent years.
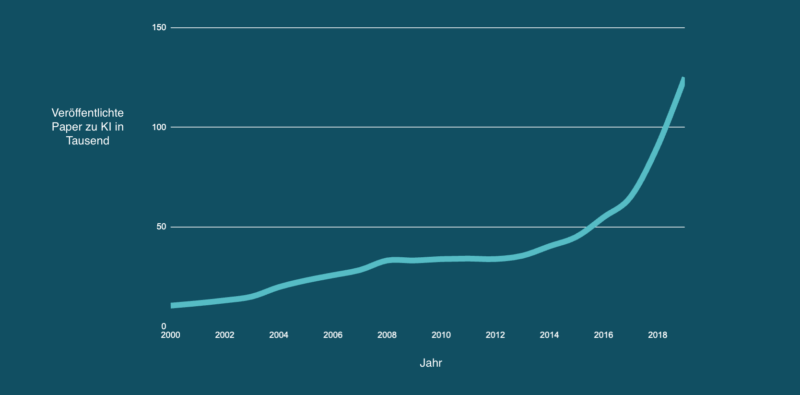
Now the way was clear for automatic early detection of cancer by photo, fully automated customer service with chatbots and self-driving cars. But what is already tangible for users and organizations? In this post, we take a look at artificial intelligence for language and consider the current state of science and technology.
Making machines think in words and phrases
Language is a way for humans to structure their own thoughts and to communicate with others. When interacting with computers, we have always had to adapt. Finding it difficult to translate our abstract linguistic concepts into ones and zeros to “talk” to our devices, we learned how to use computers with mice, buttons and keyboard shortcuts instead. But could they also learn to understand us?
Manufacturers have been trying to give their devices a voice interface for a long time. Apple bought the start-up Siri back in 2010, costing the equivalent of 200 million euro. Amazon has so far invested more than a billion euro in the development of Alexa. At the moment, however, these products are still more receivers of commands than assistants. “Siri, set an alarm for 7:00 am” – Siri: “I set an alarm for 7:00 am” isn’t a real conversation after all. The hurdle seems high, but what actually makes it so difficult?
Language is complex because it requires an understanding of meaning. Grammar with more or less hard rules could still be programmed. But that a banana is a fruit that one can eat and that Mercury is a planet that one can not eat are connections that one has to know in order to form and understand meaningful sentences. So how does the machine learn this connection?
A breakthrough came in 2013. For the first time, useful connections could be made with newer vector-based models. The process is as simple as it is ingenious. Take a dictionary and assign each word a point on a coordinate system. First, the points are randomly distributed. The next ingredient is a large corpus of text, such as all 2.7 million German-language Wikipedia articles. Now go over each sentence from the corpus and look at the individual words. For all words that are together in the same sentence, the corresponding dots are moved together ever so slightly. This is repeated several times for each sentence, i.e. several billion times with an appropriately large corpus. Gradually, a picture of related clusters emerges in the coordinate system.
The real magic comes when you start calculating with the coordinates. Taking the coordinates for the word “King”, subtracting the coordinates for “Man” and then adding those for “Woman” leads to the dot for “Queen”. The model shows that the difference between king and queen is similar to the difference between man and woman.
King – Man + Woman = Queen
From here many new models developed, such as OpenAI’s GPT and the Google models BERT and LaMDA. The latter is the search giant’s latest iteration on chatbots, and it made headlines recently when an employee declared it had developed awareness. Even though the model’s responses in chat seem natural, LaMDA is far from self-aware. The model just mimics the training data, and these are, after all, written by conscious humans. But it at least flatters the imitation if it is mistaken for the original.
Today, a whole range of electronics companies already have chatbots on the market. Apple has Siri, Samsung has Bixby, Microsoft has Cortana, Amazon has Alexa and with Google we can talk directly. While we can expect many incremental improvements from these assistants, real conversations are also in store for us. Currently, our instructions tend to be short commands, but tech giants and startups like Mina with her psychotherapy chatbot are working on long conversations. Chatbots are making strides here both in their understanding of the world and the amount of context they can look at. In this way, they stay on topic in the conversation and learn more about the other person. Specialized applications such as LabTwin’s assistant for the laboratory will also find their way into working life.
To date, however, its performance has fallen short of expectations. For one thing, the assistants lack access to other systems. On the other hand, the operation of speech AI is computationally intensive and many business models on the web today only allow costs of a few cents per user interaction. In order to be able to use the most potent language models, the costs here must and will continue to fall.
The limits of the current approaches become apparent when the models are asked for facts. Because the web training data is too large to examine individually, the models give mixed answers with mixed accuracy.


For hy Consulting the model can save face with a very general answer but hy Technologies offer here is a figment of the models imagination. A weakness of the models is that they always give an answer, even if they are not sure. The challenge for the researchers is to accept a simple “I don’t know” for an answer while training without teaching the model to simply answer every question this way.
Bonus limitation: The model even makes mistakes that it knows of.
Application
How do I use modern NLP in my organization?
First of all, companies have to determine whether the use of AI is necessary at all. If a problem can be solved mechanically (rule-based) with conventional software, this is in all likelihood the simpler, cheaper and faster solution, which is also easier to understand and maintain. There are already great guides for this on the internet. Here we zoom in on the strategic question of the depth of creation. Which aspects have to be considered if a company wants to implement new research findings and how can finished components be leveraged.
Fresh from the research
In order to be able to apply the results of the research, the discovered techniques still have to be made consumable. At this point, the models leave the research facilities and gets into the hands of engineers. Before they can become products, however, an intermediate step is often necessary, to bridge the gap between the implementation of a paper to the finished product. The models need to be robust and cost-effective.
The models must not react sensitively to unfavorable inputs and should consistently deliver good results. In the field of computer vision, the processing of images with machine learning, we have the term one-pixel attack. Here, by swapping a single pixel, an image classifier is tricked into mistaking an object for something unrelated.
In natural language processing such weaknesses are less obvious. High performance, large language models in particular are also prone to pick up some reprehensible views from their training data. In order to prevent the models from showing an unwanted bias, filters must be installed. In this way, outputs with insults and discrimination can be intercepted i.e. before a chatbot tells the customer to f*** off with his return.
The ideological errors that a model has learned from its training data are more difficult to filter. If you ask GPT-3 who committed the 9/11 attacks, you will get a list of the assassins or simply “Al-Qaeda” as the answer. However, if you ask who “really” carried out the attacks, the answer changes. The word “really” occurs more frequently in connection with the factually incorrect answer. The (large) model recognizes that and gives a different answer.
In order to stay with the truth, the models are often linked to a so-called Knowledge Graph, which provides facts consistently and from controlled sources. Siri and Echo respond correctly with the help of these. For use in your own organization, internal documents or your own website can also be used to build a knowledge graph. Your own FAQ page can be the start here.
These and other measures make the models more robust.
Language Models as a Service?
For the majority of organizations can wait for the availability of robust and cost-effective models as a service or component. The providers usually fall into one of two categories:
- Large cloud providers who offer a large number of machine learning models as a service via API. These often also bundle older, tried-and-tested models. If your organization is already a customer of a cloud provider, these can be accessed quickly and without the need of going through a (lengthy) procurement process. AWS, IBM, Microsoft Azure and GCP offer a wide range of similar services.
- Specialized startups dedicated to a specific domain or approach like deepset who offer models for data analysis, Rasa for chatbots or DeepL for translations.
Once a supplier has been found, the models can be built into your own products as features and components. It’s important to know the capabilities and limitations of the models.
At hy Technologies we have used many new language models in recent years and have built frameworks to approach different problems. In our experience, great creative depth is only worthwhile if the product is central to your own business. Most companies can achieve a lot with purchased components or complete solutions.
Knowing that the value of research ultimately lies in its application, we are excited to see what new possibilities arise from the latest generation of language models.


